
وقتی صحبت از کلان داده در سلزمان ها می شود .فرایند های رایج مثل انباشت ،ذخیره سازی به چالش خواهد افتاد چه برسد به تحلیل و پیش بینی این داده های بزرگ . در اینجا برخی از مواردی که می …
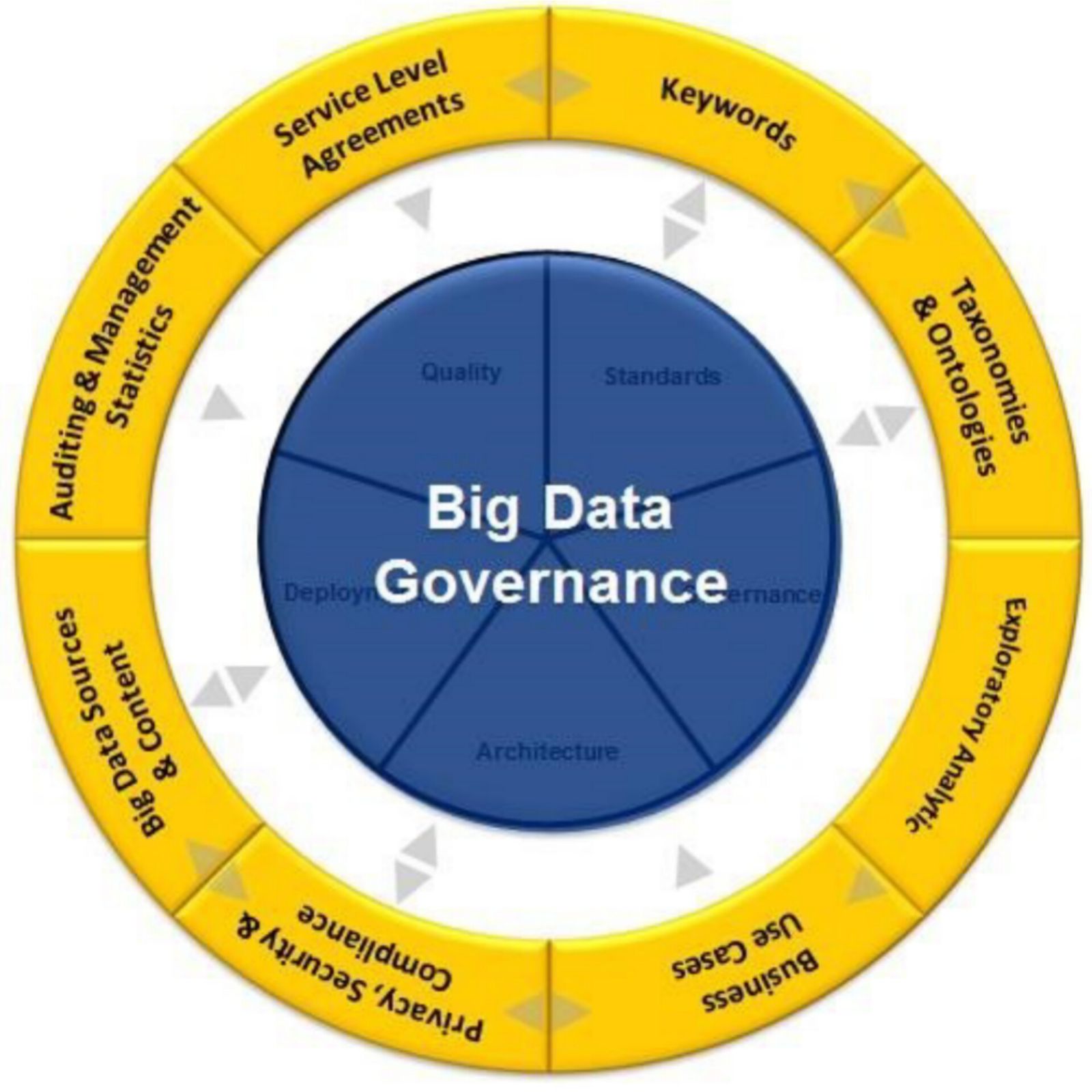
آیا بین حاکمیت داده و حاکمیت کلان داده تفاوتی وجود دارد ؟ در واقع، نباید هیچ تفاوتی بین این دو حاکمیت وجود داشته باشد .اصول یکسانی باید برای هر دو حاکمیت اعمال می شود.حاکمیت کلان داده از نظر چالش ها …

تحول دیجیتال به معنای تغییرات عمیقی است که در جوامع و اقتصادات جهانی به وجود آمده است، به گونهای که تکنولوژیهای دیجیتالی مانند اینترنت، تلفن همراه، کامپیوتر و پردازش ابری از عوامل مهم این تغییرات هستند. تحول دیجیتال در حوزههای مختلف، …
